Machine Translation Hungarian to Romanian
1st Semester of 2022-2023
Abstract
The aim of our project is to provide the first open-source Hungarian-Romanian machine translation model that is available on the largest NLP open-source community, HuggingFace. This paper details the approaches we tried, the models we trained, how we evaluated their outputs as well as a discussion on how our models compare to Google Translate and other popular translation tools such as Deepl. We also talk about the limitations that we faced and what changes would provide the most significant improvements.
1 Introduction
Machine Translation is one of the fundamental subdomains of Natural Language Processing. Since English is so popular in today’s world, especially on the internet, we use translation tools almost everyday, whether we want to be sure about the translation of a specific word or because we want to make sure our new Tweet is grammatically correct so that we won’t be attacked by keyboard warriors. Today, translation tools are very accurate and we can usually rely on their output. Even though it’s not perfect, most of the time it is enough to make yourself understood in another language. This is all great, however, most of the translation tools available are not open source: we don’t know what Machine Learning model they use, on what dataset they are trained, what solutions are used in order to improve their predictions and so on. For us, they are black boxes. We can give them an input and hope that the output is good enough.
There are some open source communities/projects that provide pretrained models for users to experiment with or finetune. The datasets on which they were trained, the hyperparameters and the results on some benchmark datasets are also provided. One of the most popular open source NLP communities is HuggingFace. They provide lots of models/datasets for different tasks. For Machine Translation, there are many models available and anyone can train/finetune a model and then release it to the public.
However, even on HuggingFace (and pretty much anywhere else, to the best of our knowledge) there is no open source model that translates Hungarian to Romanian. With this project, we wanted to change that.
In short, the approach that we used is as follows: we found a dataset of legal documents that contains Hu-Ro bitexts. We trained models from scratch on the dataset and compared them. We also evaluated some pretrained models with the pivot approach (one model for Hu-En plus one for En-Ro, for example) and compared them with our models. We then analysed the outputs of different models for the same input, including some private models, like the ones used by Google Translate and Deepl and talked about the key differences between them.
Contributions:
-
•
Teodor: researched datasets available, cleaned the DGT dataset (the one that we chose for the project), researched and trained MarianMT transformer model from scratch with the HuggingFace library. Uploaded the best transformer model on HuggingFace. Uploaded the cleaned DGT dataset to HuggingFace. Contributed to this paper as well as the presentation.
-
•
Daniel: researched datasets available, worked on cleaning another dataset before we switched to DGT. Researched and evaluated pretrained models with the pivoting approach (English, French and Finnish), trained CNN models from scratch with the fairseq library. Tried to combine the encoder of a Hu-X model with the decoder of a X-Ro model. Contributed to this paper as well as the presentation.
We chose to approach this project because we wanted to code ourselves a solution for Machine Translation with a pair of languages and see how it works and how difficult it is. We picked this pair because they are unpopular languages, there is not much research available therefore it was an opportunity of having a lot of impact (first open source Hu-Ro model on HuggingFace). Also, very importantly, there are a lot of Hungarians living in Romania. We believe that advancing the state of the art (or at least encouraging other people to do research in this direction) would benefit them.
We didn’t find research publicly available for Hu-Ro translation. Also, even though a lot of less popular language pairs have models available on HuggingFace, there is none for Hu-Ro. There are models for Hu-Fi and Fi-Ro, or Hu-En and En-Ro, and we used such models with the pivoting approach in order to compare them with our models. These models were provided by the organization Helsinki-NLP. They have trained MarianMT for a lot of language pairs and have uploaded about 1000 models to the HuggingFace Hub. We could say that we tried what worked on other language pairs because chances were that it would work on ours too. For example, Teodor used the configuration of MarianMT for En-Ro with some minor changes (vocabulary size and special tokens), but for Hu-Ro.
2 Related work
The goal of machine translation is to create automatic systems that can translate content from one language (the source) to another (the destination) without the assistance of a person. There are several kinds of solutions depending on their complexity (and effectiveness), each with advantages and disadvantages: Rule-Based Machine Translation (RBMT), Statistical Machine Translation (SMT), and Neural Machine Translation (NMT).
The first category involves rule-based techniques based on the grammars of the language by substituting each word for its translation in the location specified by the grammar rules. Despite having a nice theoretical foundation, it has been found to be incredibly ineffective in reality, particularly when it comes to determining the optimum adaptive rule for a pair of sentences and how complicated and varied grammatical rules should be. There is also the issue of conflicting rules already in place. Because Romanian and Hungarian are not part of the same family language, identifying a Rule-Based Machine Translation system would be a very challenging effort.
Until the Deep Learning revolution (about 2010), the most well-known approach was Statistical Machine Translation. These models used statistics to identify related words and phrases in a parallel / bilingual corpus. The most popular variant is phrase-based SMT, which allows for more accurate translations than the original word-to-word translation presented above. It does this by mapping phrases from the source language with phrases from the destination language. Although this method provides better translations, it still has problems with long-term dependencies (e.g. incorrect gender agreements).
Today, the most well-established method for tackling Machine Translation issues is the encoder-decoder framework, which is based on deep learning and which falls under the last category. It consists of two distinct components, which are both of a similar kind. A raw sentence (often in the form of a list of words) is converted into a fixed-sized and dense representation using an encoder. The decoder takes the latter and begins anticipating a translation word by word until it obtains a specific token, which is often used to indicate the conclusion of a phrase. The output of the encoder and its own previously anticipated words are both available to the decoder at any one time.
3 Approach
3.1 Translation using a convolutional sequence to sequence network conv-seq-2-seq-learning
Such a network consists of a fully convolutional encoder and a fully convolutional decoder, where each is followed by a non-linear layer. At training time, the outputs generated by the encoder and decoder are pushed to a dot product in order to determine the actual attention values CNN-seq-2-seq . The calculated dot product is then added together with the decoder result to (successfully) predict the target words.
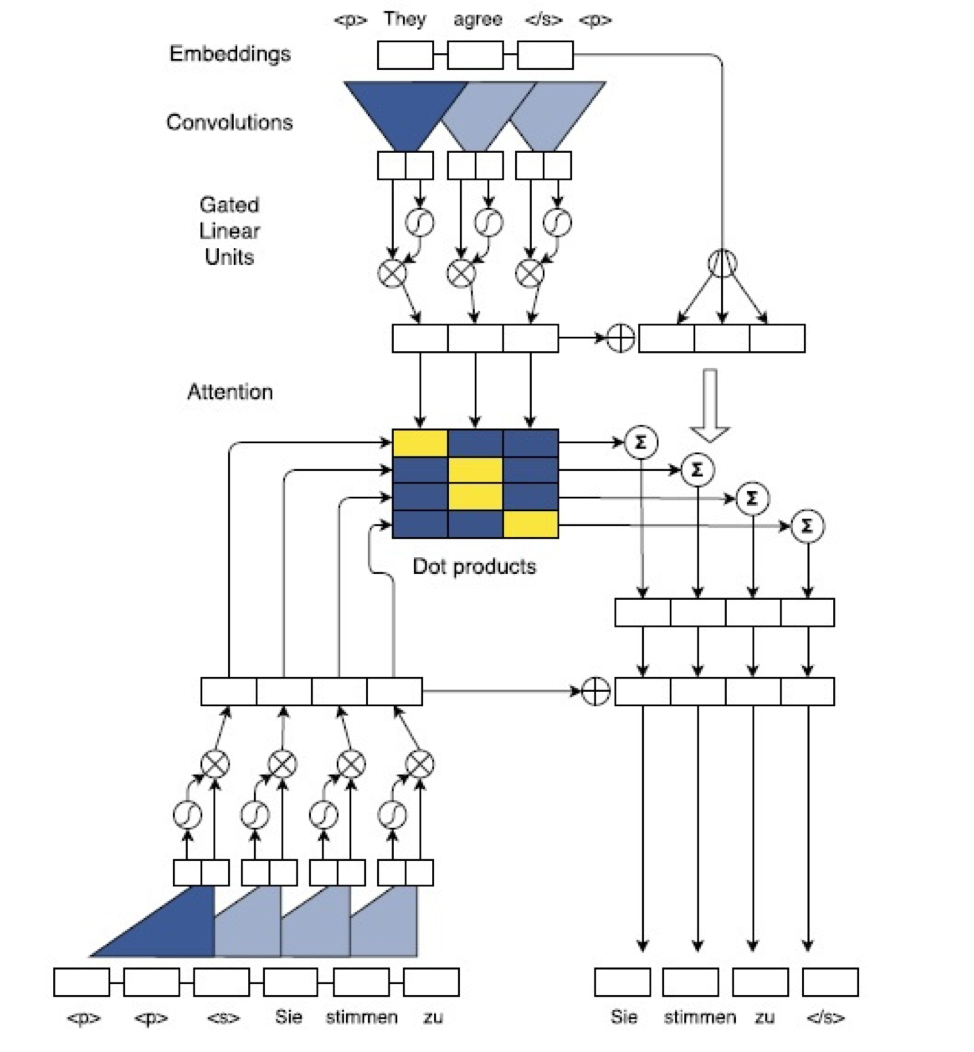
Using SentencePiece encoding we have trained the model for 11 epochs ( 13 hours including validation steps) on an NVIDIA T4 GPU. As far as hyperparameters are concerned we have chosen to use a learning rate of 0.5 (due to the hasty training for such a complex model) and label smoothing, which ensures the regularization at training time, by introducing noise to labels, which in turn results to a decreased overfitting chance. During training time the loss has steadily decreased for the first 6 epochs, after which it started to stagnate at around . The whole process was made possible using FairSeq’s CLI. Support code can be accessed at this link
3.2 Translation using the MarianMT transformer model
For most NLP tasks today, transformer models are by far the number one choice. Machine Translation is no exception. Choosing to focus mostly on transformer models was a no-brainer, since they were most likely to perform well but also since Hugging Face is designed as an open source hub for transformer models.
Our transformer of choice is MarianMT MarianMt since it is specifically designed for the task of Machine Translation. Also, it is relatively small compared to other transformer models, with around 50 million trainable parameters, depending on vocabulary size. Additionally, at the time of writing this paper, out of 1,854 models uploaded on Hugging Face for the task of translation, 1,446 are MarianMT models trained by the organization Helsinki-NLP. We tought that if it worked for so many language pairs, it might work for Hu-Ro as well.
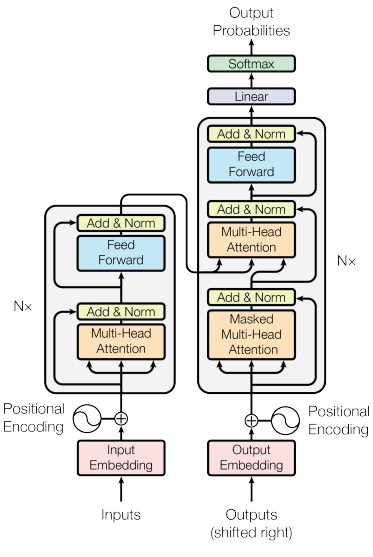
MarianMT is a transformer model with the encoder-decoder architecture. We didn’t experiment with architecture parameters since we had time and resources limitations. We used the same values that Helsinki-NLP used for their En-Ro model, apart from the vocabulary size.
Architecture parameters:
-
•
Encoder/Decoder layers: 6
-
•
Encoder/Decore attention heads: 8
-
•
Vocabulary size: 10,000 and 20,000. (different models)
-
•
Number of beams for Beam Search: 4
3.3 Translation using a pivot language Transformer model
Machine Translation research is biased towards language pairs including English due to the ease of collecting parallel corpora. Translation between non-English languages, e.g., Hungarian to Romanian, is usually done with pivoting through English pivot-translation , i.e., translating Hungarian (source) input to English (pivot) first with a Hungarian to English model which is later translated to Romanian (target) with a English to Romanian model. The most naive approach is reusing (already trained) source to pivot and pivot to target models directly, decoding twice via the pivot language.
As presented earlier, because there is no model to translate directly from Hungarian to Romanian, we used two different models with the same architecture, namely the MarianMT model, an encoder-decoder transformer with six layers in each component. All the used models (HU to pivot and pivot to RO) were pretrained by Helsinki-NLP. Regarding the pivot, we’ve tried several: English (EN), French (FR), and Finnish (FI). However, this approach requires doubled decoding time and the translation errors are propagated or expanded via the two-step process. Therefore, it is more beneficial to build a single source to target model directly for both efficiency and adequacy pivot-translation-2 . We tried to combine the Hungarian to pivot encoder with the pivot to Romanian decoder, but we couldn’t make it work because of the architecture. More exactly, MarianMT uses a shared embeddings layer, which has the size of the vocabulary. As the vocabularies for the models are different, this layer is different, therefore we can’t merge these components.
4 Results
We have used two different metrics to evaluate our models:
-
1.
BLEU (Bilingual Evaluation Understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another. Quality is considered to be the correspondence between a machine’s output and that of a human: “the closer a machine translation is to a professional human translation, the better it is” - this is the central idea behind BLEU. BLEU was one of the first metrics to claim a high correlation with human judgements of quality, and remains one of the most popular automated and inexpensive metrics.
Scores are calculated for individual translated segments - generally sentences - by comparing them with a set of good quality reference translations. Those scores are then averaged over the whole corpus to reach an estimate of the translation’s overall quality. Neither intelligibility nor grammatical correctness are not taken into account.
-
2.
BERTScore leverages the pre-trained contextual embeddings from BERT and matches words in candidate and reference sentences by cosine similarity. It has been shown to correlate with human judgment on sentence-level and system-level evaluation. Moreover, BERTScore computes precision, recall, and F1 measure, which can be useful for evaluating different language generation tasks. The original BERTScore paper bert-score showed that BERTScore correlates well with human judgment on sentence-level and system-level evaluation, but this depends on the model and language pair selected. Currently, the best model is microsoft/deberta-xlarge-mnli and it should be used instead of the default roberta-large in order to have the best correlation with human evaluation.
We have tested our models on two different datasets:
-
1.
DGT-TM. This is the dataset that we trained on. We randomly sampled 1,000 examples that the model didn’t see during training and predicted on them. Here we notice that the performance of the models that we trained is close to the performance of pretrained models used with the pivot approach. MarianMT performs significantly worse than the CNN trained with fairseq, judging by the BLEU score. We think that this is because MarianMT requires more training (something that we were not able to provide) in order to perform at its true potential.
-
2.
FLORES. This is a different dataset, it is not legal specific. The data is considerably different from the data that the model saw during training. Here, all the models trained by us perform much worse than the pretrained ones used with the pivot approach. We believe this is because the pivot models were trained on more diverse data (not just legal) therefore they are able to generalize better to non-legal data.
| Model | BLEU | BERTScore |
|---|---|---|
| MarianMT 10K | 0.30366 | 0.80587 |
| MarianMT 20K | 0.32098 | 0.80756 |
| FairSeq 10K | 0.37789 | 0.82108 |
| EN | 0.39906 | 0.83891 |
| FR | 0.41799 | 0.84285 |
| FI | 0.36026 | 0.82733 |
| Model | BLEU | BERTScore |
|---|---|---|
| MarianMT 10K | 0.06546 | 0.70479 |
| MarianMT 20K | 0.07373 | 0.70905 |
| FairSeq 10K | 0.09239 | 0.71035 |
| EN | 0.20930 | 0.80663 |
| FR | 0.18222 | 0.79673 |
| FI | 0.14829 | 0.78027 |
First off, it’s noteworthy to observe that experimenting with the pivot language provide various, sometimes better, results. For the DGT-1K corpus, the closeness between French and Romanian and the fact that they are both members of the Latin language family may make it simpler to produce better intermediary translations so that more meaning is captured before converting to Hungarian account for the difference.
Regarding the FLORES dataset, the results are a bit different. In this case, the model with the English pivot performed the best. A possible cause for this is the diversity of the dataset.
5 Comparing with online translation tools
In this section we will take 3 Hungarian sentences and look at how our MarianMT MarianMt and CNN models translate them compared to the English pivot approach, Google Translate and Deepl.
Sentence 1:
HU: A VIIa. melléklet e rendelet mellékletének megfelelően módosul.
RO: Anexa VII a se modifică în conformitate cu anexa la prezentul regulament.
Translations:
-
1.
Google: VIIa. anexa se modifica in conformitate cu anexa la prezentul regulament.
-
2.
Deepl: Anexa VIIa se modifică în conformitate cu anexa la prezentul regulament.
-
3.
MarianMT: Anexa VIIa se modifică în conformitate cu anexa la prezentul regulament.
-
4.
CNN: Anexa VIIa se modifică în conformitate cu anexa la prezentul regulament.
-
5.
En pivot: Anexa VIIa se modifică în conformitate cu anexa la prezentul regulament.
We notice that all models translate the sentence perfectly, apart from Google Translate. However, Google only switches the places of the first two words.
Sentence 2:
HU: A relatív válaszjel faktor meghatározására szolgáló oldat.
RO: Solutie pentru determinarea factorului de răspuns relativ.
Translations:
-
1.
Google: Solutie pentru determinarea factorului de semnal de răspuns relativ.
-
2.
Deepl: Solutie pentru determinarea factorului de răspuns relativ.
-
3.
MarianMT: Solutie de determinare a corespondentei relative.
-
4.
CNN: Solutie de determinare a factorului de răspuns relativ.
-
5.
En pivot: Soluţie pentru determinarea factorului de răspuns relativ.
Here we notice that Deepl and the En pivot translate the sentence perfectly. Google adds an additional word “de semnal”. The CNN uses “de” instead of “pentru” which is a negligible issue, while MarianMT also replaces “factorului de raspuns” with “corespondentei”, therefore its translation is considerably worse compared to all other approaches, but the meaning of the sentence is largely preserved.
Sentence 3:
HU: A Crédit Mutuel az ügy elhúzódását rója fel a Bizottságnak.
RO: Crédit Mutuel reprosează Comisiei durata extrem de îndelungată de solutionare a cauzei.
Translations:
-
1.
Google: Crédit Mutuel acuză Comisia că a amânat cazul.
-
2.
Deepl: Crédit Mutuel dă vina pe Comisie pentru această întârziere.
-
3.
MarianMT: Initutia Crédit Mutuel este obligată Comisiei să retragă retragarea cauzei.
-
4.
CNN: Crédit Mutuel îsi dă acordul cu privire la acest aspect.
-
5.
En pivot: Crédit Mutuel dă vina pe Comisie pentru întârzierea cazului.
Here we see that Deepl, Google and En pivot keep the sense of the sentence mostly intact, but rephrase it. MarianMT and the CNN on the other hand perform very poorly on this particular sentence. MarianMT in particular produces two words that are grammatically incorrect: “Initutia” and “retragarea”.
We see that there is still space for improvement. We believe that training MarianMT on a larger dataset (we used only 400,000 bitexts) and for more epochs (we trained for 10 epochs) would significantly improve its performance. A hint for this is the fact that the training loss was still decreasing significantly even after the 10th epoch.
6 Limitations
Given the fact that we had access to limited free resources and time to research/train, we naturally encountered a lot of limitations. Also, the models that we trained have some corpus specific limitations worth mentioning. We will now list the key issues of our work/approach:
-
•
GPU: we have used Google Colab for all our training/experiments. The machine that we had at our disposal had 12 GB RAM and a Tesla T4 GPU with 15GB VRAM. The maximum batch size that we were able to use with MarianMT was 64, but only if we did no evaluation while training. Still, the training took about 45 minutes per epoch. We were able to train for a few hours before Colab would kick us out for using the GPU for too long. Then we had to wait for almost a whole day to have access to the GPU again. This slowed us down and didn’t allow us to train for a long time (and Transformers are known to require a lot of training).
-
•
Time: we wanted to try multiple models with multiple vocab sizes and then compare them. However, we quickly realised that in order to do that, we need to train only on a small portion of the whole DGT-TM corpus, because with only one GPU and limited access to it, it would take us until the exam session of the next semester to actually have some results. Therefore, we used only 400,000 out of all 2,180,266 bitexts in the dataset for training. For testing, we used only 1,000 examples since at test time models use beam search to generate output and it takes about 30 minutes to predict on 1,000 examples.
-
•
Dataset: we chose to train on DGT-TM, a corpus of European Union laws translated in over 20 languages, among which Hungarian and Romanian. Most of the texts are aligned pretty well. However, there are some with really poor alignment (we didn’t correct their alignment, that would be perhaps an entirely different task). Also we found examples in french and examples that simply were missing some words. We tried our best to filter some of examples that were unlikely to help our models: examples shorter than 3 words, examples that are 3 times (or more) larger in one language than in the other and empty examples.
-
•
Domain: we chose to train on a legal corpus, therefore our models do pretty well on legal specific data. If we evaluate them on other datasets that are not legal specific, they perform pretty poorly, as we can see from the results on FLORES.
7 Conclusions and Future Work
We believe that we have achieved our main goal: making a Hu-Ro translation model publicly available. The model can be downloaded from Hugging Face hub and anyone can use it directly from the Hugging Face UI at the following link.
There are however things that can be improved. We believe that there are three main steps that would greatly benefit the project, in the future:
-
1.
Use a machine with multiple GPUs that allows for continuous training for a long time (weeks). This way, the whole dataset could be used for training (>6 time more data than we used) and the results would be much better.
-
2.
Experiment with hyperparameters like vocabulary size (we only tried with 10,000 and 20,000), learning rate, learning rate decay, embedding size etc. We saw that our model trained with vocabulary size 20,000 performs better than the one trained with vocabulary size 10,000, maybe increasing it even further will keep upgrading the model.
-
3.
If we want the model to perform well not only on legal data, we could build a more complex multi-domain corpus and train on it. The models available on Hugging Face, trained by the organization Helsinki-NLP perform pretty well on the FLORES dataset as well, which makes us think that they were trained on more diverse data.
References
- (1) Marcin Junczys-Dowmunt, Roman Grundkiewicz, Tomasz Dwojak, Hieu Hoang, Kenneth Heafield, Tom Neckermann, Frank Seide, Ulrich Germann, Alham Fikri Aji, Nikolay Bogoychev, André F. T. Martins, Alexandra Birch (2018) Marian: Fast Neural Machine Translation in C++
- (2) Maha Elbayad, Laurent Besacier, Jakob Verbeek (2018) Pervasive Attention: 2D Convolutional Neural Networks for Sequence-to-Sequence Prediction
- (3) Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N. Dauphin (2017) Convolutional Sequence to Sequence Learning
- (4) Hua Wu and Haifeng Wang Revisiting Pivot Language Approach for Machine Translation
- (5) Yichong Leng, Xu Tan, Tao Qin, Xiang-Yang Li, Tie-Yan Liu (2019) Unsupervised Pivot Translation for Distant Languages
- (6) Bogdan Babych, Anthony Hartley, Serge Sharoff Translating from under-resourced languages: Comparing direct transfer against pivot translation
- (7) Ilya Sutskever, Oriol Vinyals, Quoc V. Le (2014) Sequence to Sequence Learning with Neural Networks
- (8) Kunjin Chen, Qin Wang, Ziyu He, Kunlong Chen, Jun Hu, Jinliang He (2018) Convolutional sequence to sequence non-intrusive load monitoring
- (9) Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, Yoav Artzi (2019) BERTScore: Evaluating Text Generation with BERT